
How to Prevent a Tragedy of the Commons for AI Research?
I publish in both journals and conferences (ICML, NeurIPS, ICLR). While I can often predict whether my journal submissions will be accepted, it is much harder to do so for conference papers. Occasionally, a submission I consider strong is unexpectedly rejected, while some pieces I regard as merely adequate get accepted. I suspect this experience is widespread; indeed, the unpredictability of the peer review process at these conferences is a common complaint on social media.
Part of the reason lies in the explosive growth of submissions in recent years. From 2016 to 2024, NeurIPS submissions grew from 2,425 to 15,671, averaging a 26.3% annual increase, while ICML submissions jumped from 6,538 in 2023 to 9,653 in 2024 (a 47.6% increase in just one year). To handle this surge, conferences must recruit many junior researchers—often PhD students or even undergraduates—to serve as reviewers.
While I lack direct evidence, I would argue that this rapid growth, coupled with relatively inexperienced reviewers, risks creating a “tragedy of the commons”: as more authors submit, review quality declines since the pool of experienced reviewers (the resource) does not grow as much, and as review processes become arbitrary and random, more authors feel they might “get lucky” and tend to submit more, accelerating the cycle. Indeed, it is not uncommon these days to see high school students submit papers to these conferences.
If this tragedy becomes a reality, it would be devastating to research. It would become more difficult for researchers from less prestigious institutions to make their research visible even when published in these conferences, since the distinction between arXiv preprints and conference proceedings would diminish. In the long run, if the consensus emerges (as I believe it is beginning to) that peer review in ML/AI is of poor quality, people—especially the younger generation—would be less likely to maintain a sense of honor when undertaking review responsibilities. After all, reviewing papers does not directly benefit one’s career; devoting valuable time to this task requires a sense of honor and voluntary responsibility to the community.
A no-cost solution
During an afternoon in November 2020, I conceived an idea: since I know or have a good sense of the quality of my own submissions, why can’t I be a reviewer of my own submissions? Of course, one generally wouldn’t tell the truth if asked about the absolute quality of their submissions. Perhaps the right approach is to ask for pairwise comparisons, or more specifically, a ranking of the submissions one author submits to a single conference. Given a ranking, the simplest approach to modify the review scores would be to project the raw scores onto the cone specified by the ranking.
We call this method the Isotonic Mechanism because it is essentially isotonic regression, which possesses many desirable properties due to its convex nature. It’s not difficult to prove that authors would provide true rankings if they want to maximize their utility as a convex function of modified review scores. Then isotonic regression with a truthful ranking would significantly enhance estimation accuracy. A notable feature of this mechanism is that rankings can be formed by pairwise comparisons. As we know, pairwise comparisons are straightforward to perform. Everyone has biases—some may score 8 for a good paper, while others may think 5 is already high. But pairwise comparisons are free of this bias and can be well calibrated. Indeed, pairwise comparisons are also the form of data that OpenAI collected from human labelers for training its reward model.
The benefits extend beyond truthfulness. Under certain conditions, we show that ranking is the most fine-grained information that one can truthfully elicit from the author. That is, the Isotonic Mechanism is the optimal truthful mechanism. Moreover, it is essentially cost-free as it doesn’t increase the burden for reviewers at all!
For technical details regarding the Isotonic Mechanism, please see the slides.
Experiments at ICML
Despite its many favorable properties, finding the right occasion to test the Isotonic Mechanism turned out to be challenging. Fortunately, I got approval from the ICML PCs to conduct an experiment at ICML 2023. This opportunity would not have been possible without help from Didong Li and Sherry Xue.
In the experiment, authors voluntarily submitted rankings of their submissions through our website, OpenRank. We collected 1,342 rankings covering 2,592 submissions. Analysis showed that the ranking-calibrated scores outperform raw scores in approximating the “expected review scores.” (See the figure below.)
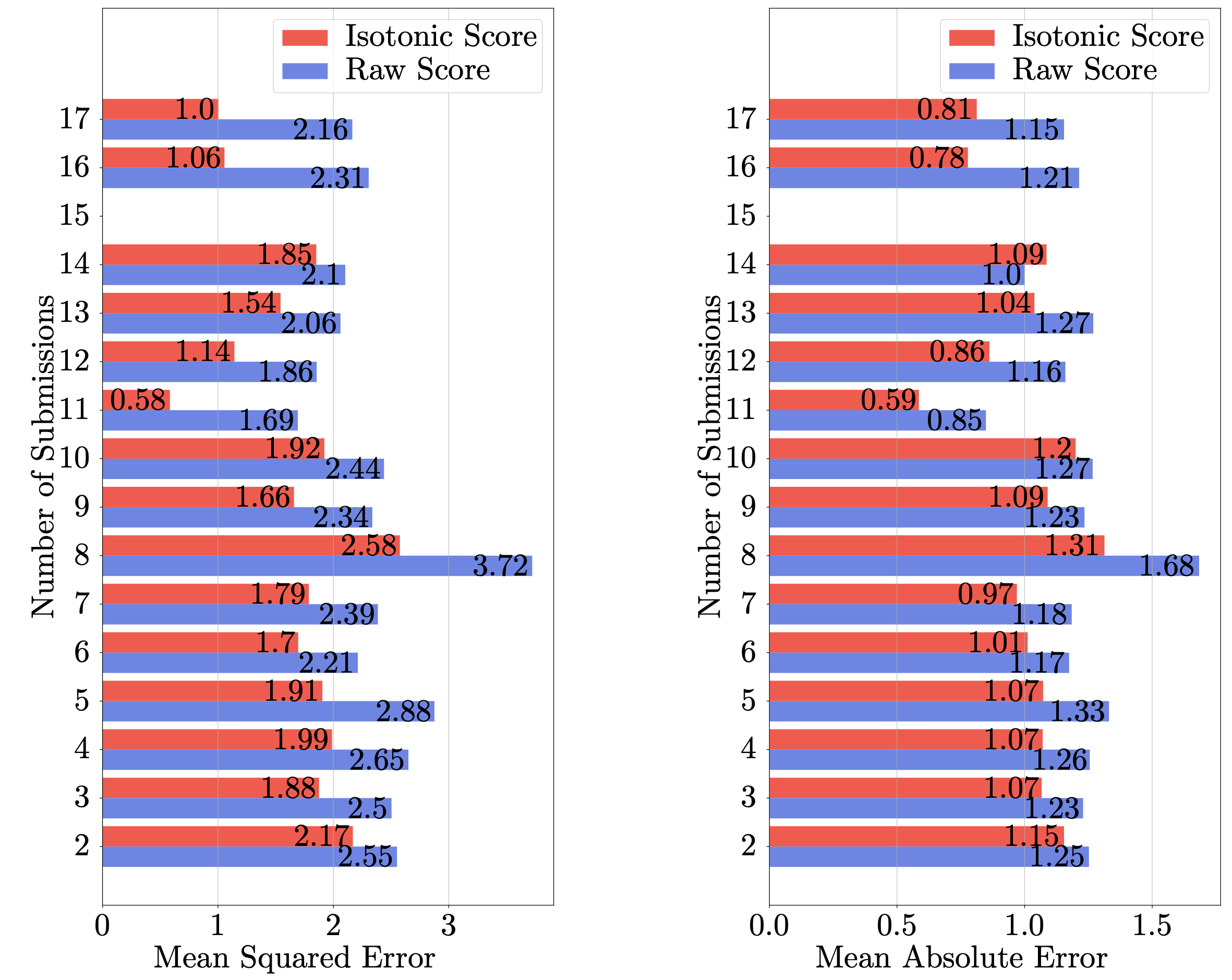
We continued this experiment at ICML in 2024 and 2025, integrating the ranking collection function into OpenReview. This integration now makes it straightforward to deploy the Isotonic Mechanism for larger-scale tests. A special acknowledgment goes to Buxin Su for making substantial contributions to these efforts.
Near-term applications
While it might take longer to adopt the Isotonic Mechanism in real decision-making processes, below are some potential immediate applications of these isotonic scores that introduce minimal risk yet offer a safeguard against overlooked nuances in scientific contributions.
-
Enhanced oversight by Senior Area Chairs (SACs).
The isotonic scores can be visible solely to SACs and higher-level roles, enabling them to flag submissions in need of more scrutiny. For instance, a substantial discrepancy between isotonic scores and Area Chair recommendations could prompt additional review or discussion. -
Award selection.
Many ML/AI conferences designate a shortlist for potential awards—usually high-scoring papers or those nominated by ACs. Including author-provided rankings in the final deliberations could offer an additional verification mechanism. For example, if a paper recommended for an award receives notably low rankings from its authors, the committee might investigate further before finalizing its decision. -
Emergency reviewer assignment.
Conferences often enlist emergency reviewers when there is low-confidence or contradictory feedback from existing reviews. Large discrepancies between raw scores and the isotonic scores may help identify submissions needing urgent attention.
References
- Analysis of the ICML 2023 Ranking Data: Can Authors’ Opinions of Their Own Papers Assist Peer Review in Machine Learning? B. Su, J. Zhang, N. Collina, Y. Yan, D. Li, K. Cho, J. Fan, A. Roth, and W. Su.
- Isotonic Mechanism for Exponential Family Estimation in Machine Learning Peer Review. Y. Yan, W. Su, and J. Fan. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 2025+.
- A Truth Serum for Eliciting Self-Evaluations in Scientific Reviews. J. Wu, H. Xu, Y. Guo, and W. Su.
- You Are the Best Reviewer of Your Own Papers: The Isotonic Mechanism. W. Su.
- You Are the Best Reviewer of Your Own Papers: An Owner-Assisted Scoring Mechanism. W. Su. Neural Information Processing Systems (NeurIPS), 2021.